Here's an example of something I came across for Azure SQL Database V12 that I don't see documented anywhere (yet): You can change the compatibility level of an Azure SQL Database.
Image may be NSFW. Clik here to view.Enough talk of the GUI with Extended Events (see previous articles in the series if you want to revisit the stickiness of the GUI – here). It is time for a bit of a diversion and something quick.
While it may be a quick traipse today, it won’t be the last article on the subject. It is merely an interesting bird walk into a corner of the Extended Events garden that is seldom visited. Today I will explore the little function called sys.fn_MSxe_read_event_stream.
This function, as the name implies, is used to read the event stream and is most commonly seen when watching the live stream of events for a session. I will show a little bit of that.
Gradually Descending into the Stream
First, let’s set the stage so you can confirm that I am not entirely off my rocker here.
By selecting “Watch Live Data” from the context menu after right clicking on the “system_health” session, I will be given a window just like the window discussed in the past few articles when discussing the GUI. After launching that window, a quick query to your favorite requests and sessions DMVs will reveal a little bit about this function we are diving after today.
If I click on the query text in that previous result set, I can see the following to be the query that is executing for the “live data” stream.
(@source nvarchar(256),@sourceopt int)
SELECT type, data
FROM sys.fn_MSxe_read_event_stream (@source, @sourceopt)
Cleaning it up a bit and giving some useful values to the parameters, I might have something like this:
/* read from livestream */
DECLARE @source NVARCHAR(256) = 'system_health'
, @sourceopt INT = 0;
SELECT type
, data
FROM sys.fn_MSxe_read_event_stream(@source, @sourceopt);
Running that particular query from a management studio window would be rather pointless. It doesn’t ever return unless you cancel the query. The key to this one though is the second parameter. The second parameter tells us what kind of source we want to use for the stream of data. There are two values (that I have been able to find) that can be used: 0 and 1. A value of 0 pulls from the live stream target. A value of 1 pulls from the file target. If using a value of 1, then the first parameter needs to be adjusted accordingly as well. If the two parameters do not match, then an error is thrown.
/* read from file */
DECLARE @source NVARCHAR(256) = 'system_health_*.xel'
, @sourceopt INT = 1;
SELECT type
, data
FROM sys.fn_MSxe_read_event_stream(@source, @sourceopt)
;
GO
As it happens, I have several log files in the default directory for the system_health and the HKEngine sessions that are deployed and running on my instance of SQL Server. Here is a sample of those files:
This to me is far from useful as of yet. But there are a couple of rabbit holes to dig into from here. The first being the different types that we can see here. Let’s refashion the query to restrict the types being returned and see what happens:
First, in blue we see that type 2 is exactly the same every single time. In my environment I have exactly four of that type. If I look on the file system, I can see that I have four files as well. This seems to indicate (not yet validated in my plucking at it) that this represents a file. Then type 1 is identical up until the point where I have it highlighted in orange. Just an interesting side note there is all.
If I perform the same thing for the HKEngine session, I see something like the following:
Notice the difference here? Now I have two type 1 entries for each file that has been created. In addition, one of the type 1 entries is exactly the same for all files created.
But without being able to translate the data returned, this is really just a fun exercise into the live stream. That said, I give you one last interesting tidbit for today while leaving the second rabbit hole (translating the data into human readable text) for another time (besides just using the event file function to read it).
DBCC OUTPUTBUFFER(53)
Recall from an earlier result that my spid for the live data viewer was spid 53. If run an output buffer for that spid, I will see something like the following:
Not the friendliest of outputs to peruse and try to figure out, but it does give you a sense of what is going on there. If you know how to convert the data output from sys.fn_MSxe_read_event_stream, I would be interested in seeing what you do for it.
This has been another article in the 60 Days of XE series. If you have missed any of the articles, or just want a refresher, check out the TOC.
I found a bug where I’m seeing TempDB use more memory than it should. While I’m almost certain that the issue is in SQL Server and not my query, especially since I saw results in my workaround, I wanted to put this out here and discuss the issue before opening a connect item.
Querying the Buffer Pool
I have a query to show me what’s in the buffer pool for the entire server, with my newest version of the script in my post that went out yesterday called Querying the Buffer Pool. It shows number of pages in the buffer pool grouped by the database, table, and index. The query makes use of left joins so it can see space in memory that’s not currently allocated to a specific object.
The results are surprising in many ways.
The good surprises are seeing what indexes are hogging up your buffer pool so you have an idea of where to start tuning. I’m a huge fan of this and have blogged about it in Cleaning Up the Buffer Pool to Increase PLE, although the name of my older post is misleading because it does more than just help memory management in SQL Server. Since I wrote that post I rewrote that script enough where it deserved to be put out there again in Querying the Buffer Pool, but it was robust enough to find what I believe may be a bug in SQL Server.
The Bug
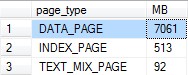
The bad surprise was a bug which has been harassing me for quite some time now. As I mentioned, the query will return all the space in the buffer pool, specifically the contents of sys.dm_os_buffer_descriptors, and does a left join to the tables leading up to and including sys.indexes so space not currently allocated to a table will show up. The problem is that the space that shows up as unallocated for TempDB is much larger than expected, in this case taking up 1/3 of my buffer pool.
Image may be NSFW. Clik here to view.
On this post I’m talking about a single server, but the problem wasn’t limited to a single server. It showed up at the same time, caused by the same change, partially resolved by the same partial rollback on SQL 2008 R2, SQL 2012, and SQL 2014.
I tried telling TempDB if you can’t swim nicely with the others then get out of the pool, but it did not listen to my version of logic.
Details About the Bug
So the query I have on today’s earlier post Querying the Buffer Pool showed I had unallocated space in TempDB in memory, and a lot of it. However, it doesn’t show details.
To start looking at the details, what kind of pages are these that exist in sys.dm_os_buffer_descriptors, but not in sys.allocation_units?
SELECT bd.page_type
, MB = count(1) / 128
FROM sys.dm_os_buffer_descriptors bd
LEFT JOIN sys.allocation_units au ON bd.allocation_unit_id = au.allocation_unit_id
WHERE bd.database_id = 2 --TempDB
AND bd.is_modified = 0 --Let's not play dirty, only clean pages
AND au.allocation_unit_id IS NULL --It's not even allocated
GROUP BY bd.page_type
ORDER BY 2 DESC
Image may be NSFW. Clik here to view.
Ok, so we’re dealing with typical data in TempDB. Well, other than it not being allocated, of course.
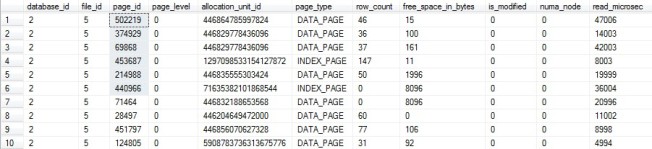
So I run another query to get more details. This time I want to look inside the pages to see if they tell a different story.
SELECT TOP 100 bd.*
FROM sys.dm_os_buffer_descriptors bd
LEFT JOIN sys.allocation_units au ON bd.allocation_unit_id = au.allocation_unit_id
WHERE bd.database_id = 2 --TempDB
AND bd.is_modified = 0 --Let's not play dirty, only clean pages
AND au.allocation_unit_id IS NULL --It's not even allocated
Image may be NSFW. Clik here to view.
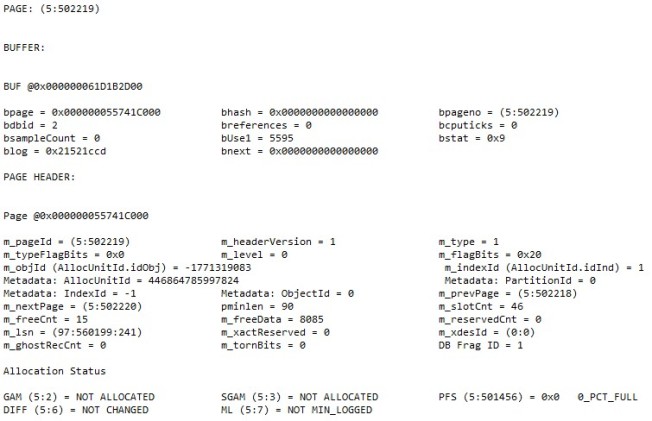
Then I follow that up with Paul Randal’s How to use DBCC PAGE, which comes with all the disclaimers about using an undocumented and unsupported trace flag and command. This one isn’t horrible in my mind or Paul’s comments, but remember the undocumented and unsupported parts.
There are several important parts to me. The m_objId is a negative value I can’t find in TempDB.sys.objects, so it WAS a temporary object that no longer exists. Across the board, these are “NOT ALLOCATED”, “NOT CHANGED”, “NOT MIN_LOGGED”, “0_PCT_FULL”, so there’s nothing there.
To me it looks like temp objects made it into memory and remained in memory after the temporary objects were dropped. I have no idea what objects these were or how they were dropped, but I’m imagining these were temp tables automatically dropped when the session was either closed or reset.
A Recent Change (A CLUE)
I found this by noticing that PLE for several servers was lower now than it has been in the past, so I was peeking in the buffer pool to see who was playing nice. Going off of “when did PLE start to be lower” I noticed that I implemented a change around that time to use a common best practice.
TempDB data files were now presized to take up a vast majority of the dedicated LUN. It avoids waiting for file growth, especially if you’re using TDE (I’m not) and can’t use IFI (I can), but for several other reasons as well including file fragmentation and the slight pause even IFI causes. So at the start of all these festivities, I took the 4 TempDB data files from 100 MB each to 12 GB each using up 48 GB of the 50 GB available.
A Workaround
Seeing this, I wanted to partially roll back the change the next opportunity I had. 100 MB was too small and I was aware that it invoked file growths every month (we reboot monthly for OS updates). 48 GB wasn’t right though, we just have that much space on the drive due to server build standards and paranoia (I’m a DBA). So I went through our Idera Diagnostic Manager monitoring software and found the most space TempDB used, which is captured once an hour. I found that 4.8 GB was the peak usage with several incidents of usage going over 4.5 GB.
With that information available and still not wanting an autogrowth for all the reasons listed above, I decided that all 4 files should be 1.5 GB, so 6 GB total. That means peak usage was about 75% full, leaving plenty of room for error, especially with my baseline only be captured once an hour. Autogrowth is set to 256 MB, so it’d add 1 GB total each growth. I can live with that.
I can’t say it eliminated the issue because I still have 2 GB of unallocated TempDB space in cache, but it’s better than 8 GB. It can be considered more acceptable than other issues I need to tackle right now, but it still bugs me.
What’s the Best Practice?
It’s a best practice to have TempDB data files on their own LUN, drive, array, however you want to word it. Then it just make sense to have the total size of your data files add up to 90% or more of the drive size. I see this advice everywhere, with these two standing out:
“Next, if you can give tempdb its own disk, then configure it to almost fill the drive. If nothing else will ever be on the drive, then you’re better off setting it to be larger than you’ll ever need. There’s no performance penalty, and you’ll never have to worry about autogrow again.”
“Notice that I don’t have filegrowth enabled. You want to proactively create the TempDB files at their full sizes to avoid drive fragmentation.”
Jonathan Kehayias does it a little bit differently in his post SQL Server Installation Checklist saying to add space to TempDB files in 4 GB increments. Although he doesn’t fill the drive by default, this isn’t mentioned by him, either.
Now I need to be perfectly clear on this, I trust these three sources. I trust Jonathan and Brent more than I trust myself with setting up SQL Server. I also feel the same about the authors I know on the Solar Winds post. This does not change that.
Sizing TempDB like that often means it’s much larger than you need. The workaround I’m using is to right-size these files instead. For me, for now, I’m going to stick with seeing how large TempDB gets and make it slightly larger than that until I have a solid answer to my problem.
What Was It?
I still don’t know. The workaround managed to knock it off of my priority list enough where I’m not actively working on it. However, my drive to understand SQL Server better won’t leave me alone.
This post is my solution. I have some very intelligent people reading this who I hope will at least lead me further down the rabbit hole, even if they don’t have a conclusive answer. There’s a good chance I’ll be asking for help on Twitter with #sqlhelp or opening a connect item on this, for which I have a very well documented description of the issue that I can link to.
This post is a little later than normal. It’s been a very busy few weeks with family over until the 3rd of January.
Well 2015 was a hell of a year for my blogging. I recorded just under 250k page views (244,305) which isn’t even all of them (2016 will be the first year that I get a truly complete set of data as I’ve not got page view images on every blog post that I’ve written).
This years top 10 posts look a lot more different from the prior year than has happened in earlier years.
Of the top 10, only three were in the top 10 before (numbers 1, 2 and 3 from 2014 were 4, 2, and 1 in 2015 respectively). Number 8 from 2015 was number 22 last year. Everything else in the top 10 appears to be a new post from 2015 (or didn’t have a tracking image until this year). This is pretty shocking to me. I haven’t seen the numbers shift like this before, granted that could be do to better data. Next years numbers will be interesting to see once I have a full years worth of data to look at.
Image may be NSFW. Clik here to view.Despite the desire to get away from the GUI talk in these articles about Extended Events, I have so far been unable to do it. Each article of late has something more to deal with the user interface. Let’s see what we can do with the GUI today.
One of the more useful troubleshooting tools (granted when used properly and not with a knee jerk approach) is waits. There are waits in SQL Server that are very specific to Extended Events. Not all waits are bad. Some are innocuous. But with a shoot from the hip approach, these waits can cause many DBAs to focus on the wrong thing.
In this article, I will show one particular wait for Extended Events. As a matter of fact, if you were paying attention to the last article, you will have already seen this wait in passing. To get a quick glimpse or to recall what was discussed, please read the article about the live stream target here.
Patience Padowan
The first thing I want to do is clear my wait stats. Here is a quicky on doing that. Understand that this clears out the wait stats and resets the counters to 0. If you track your waits on a regular basis, this may cause a raised eyebrow by your team-mates.
DBCC SQLPERF("sys.dm_os_wait_stats",CLEAR);
After clearing my waits, I can check for a baseline. When checking for this baseline it is important to note that I have nothing ready from an extended event target currently. I will start that after getting my baseline. Here is what my waits look like prior to working with the target data from any XEvent Session.
This is pretty vanilla prior to working with the targets. That is a good thing for now. This gives me a good sense that the baseline is a good starting point. Now, similar to what was shown in the live stream article previously mentioned, I am going to open a live stream viewer for the system_health session. At this point, you could wait for a minute or three and then re-query the waits. This additional step would be to help show that the XE wait has not yet introduced itself.
Perfect. Now I have a live stream viewer open for the system_health session. I have a good baseline. Now I just need to watch the viewer for a bit. I am doing this to ensure enough time has passed by that my waits have incremented. After a few events pop into the system_health session, I will re-query my waits.
Look at how that wait has zoomed clear to the top! This wait is huge! This wait does not appear until the “Watch Live Data” option is being used to tap into the streaming target (really should be anything that is tapping into the live stream target via the GUI or via some other program). An example of “some other program” could be as simple as somebody querying the sys.fn_MSxe_read_event_stream function from management studio and trying to return the live stream data (as was discussed in the previously mentioned article).
Not understanding what causes the XE_LIVE_TARGET_TVF wait type can cause a data professional, or two, to chase their tail on something that may not be an issue overall. I have seen this happen on more than one occasion where somebody has spent hours trying to chase down the problem that this wait indicates. It doesn’t necessarily indicate a problem (unless you are a shoot from the hip gun-slinging troubleshooter type). It just means thtat the process accessing the live stream is waiting for more data to come through. That said, if this wait is high, maybe it is time to look into who might be tapping into the Live stream target.
Pretty straight forward and short today. I hope this helps avoid some time-waste for something that can be ignored most of the time.
This has been another article in the 60 Days of XE series. If you have missed any of the articles, or just want a refresher, check out the TOC.
You’re going to see more content coming out of this site. Most of my posts are technical and they’re based on SQL lessons learned in a very busy OLTP SQL Server environment. I do my best to make each one accessible for everyone without shying away from tricky topics.
If the posts come too frequently, you’re going to be tempted to “mark all as read”. But I think most readers will easily be able to keep up with one post a week.
Image may be NSFW. Clik here to view.
So how do you stay up to date? Via Twitter
In 2016, you can count on a blog post every Wednesday. But how do you want to get them? If you found my site via twitter, consider subscribing if you want to keep up with this site.
Via RSS
If you’ve already subscribed to the RSS feed, you’re going to continue to get them as you always have, but the world seems to be moving away from RSS.
Via email (new!)
And if you want to get these posts in your inbox, I’ve set up a mailing list so you can subscribe at my site. (The mailing list is new, I set it up with tips from Kendra Little).
Continued Illustrations
Those familiar with this site know that I like to draw. It’s fun to combine that hobby with the blog. And I’m going to continue to include illustrations when I can.
Now Using SVG
One change is that I’m going to start including the photos as svg files instead of png. Basically I’m switching from raster to vector illustrations. The file sizes are slightly larger, but they’re still measured in KB. If you do have trouble looking at an illustration, let me know (include device and browser version).
Have fun zooming! If you do, you get to see lots of detail (while I get to notice the flaws).
Talking About Parameter Sniffing
I wrote a talk on parameter sniffing called “Something Stinks: Avoiding Parameter Sniffing Issues & Writing Consistently Fast SQL”.
I gave the talk to work colleagues and I’m really happy with how it went. One No-SQL colleague even told me afterward “I miss relational data.”
You get to see it if you come to Toronto next Tuesday (January 12, 2016) where I’ll be giving the talk for the user group there. Register here.
Or you get to see it if you come to Cleveland for their SQL Saturday (February 6, 2016). Register for that here.
Cheers! And Happy New Year!
Image may be NSFW. Clik here to view.Image may be NSFW. Clik here to view.
MSDTC is frequently required when using transactions within SSIS. And not just when you are connecting to two SQL Server instances.
Disclaimer: Neither SSIS nor MSDTC are my strongest skills. So while the information here is correct (to the best of my knowledge) I won’t make any claims as to it’s completeness.
tl;dr; The MSDTC service has to be not only turned on, but configured on all of the machines involved. Including the machine running the SSIS package (possibly a workstation).
So first what is MSDTC? MSDTC is Microsoft’s Distributed Transaction Coordinator service. It’s used to coordinate multiple data sources within a single transaction.
Next, you were aware that you can have transactions within an SSIS package correct? It’s pretty simple. You can follow the link for instructions.
To the best of my knowledge if you create an SSIS package you need to have MSDTC enabled if more than one machine is involved. The most obvious occurance of this is when you actually have multiple data sources. But it can also happen when the SSIS package is being run on a machine that is not one of the data sources. For example, running the package from a workstation and connecting to a test instance (that isn’t on the workstation).
Seems fairly obvious right? Well one of my co-workers set up one of these SSIS packages and was getting the following error:
SSIS package "CATS-Package.dtsx" starting.
Information: 0x4004300A at Data Flow Task, SSIS.Pipeline: Validation phase is beginning.
Information: 0x4001100A at CATS-Package: Starting distributed transaction for this container.
Error: 0xC001401A at CATS-Package: The SSIS Runtime has failed to start the distributed transaction due to error 0x8004D01B "The Transaction Manager is not available.". The DTC transaction failed to start. This could occur because the MSDTC Service is not running.
SSIS package "CATS-Package.dtsx" finished: Failure.
“The Transaction Manager is not available.” Well that was rather odd since we have MSDTC running on all our SQL Servers. After a week or so of dead ends I realized I was stuck. As you may know once I’m stuck I follow my 20 minute rule. Well, maybe a bit longer than 20 minutes. Basically if I’m stuck I go looking for help. So since this wasn’t a question I could pose in 140 characters I posted my problem on SE. Over the next few weeks I was given several pieces of advice and finally tracked down an answer.
MSDTC had to be turned on on the workstation (or application server) that SSIS was running from. That’s easy enough. Just turn on the service right? I did that, and then got the following error:
Information: 0x4001100A at CATS-Package: Starting distributed transaction for this container.
Error: 0xC001402C at CATS-Package, Connection manager "connectionName": The SSIS Runtime has failed to enlist the OLE DB connection in a distributed transaction with error 0x8004D024 "The transaction manager has disabled its support for remote/network transactions.".
Error: 0xC0202009 at CATS-Package, Connection manager "connectionName": SSIS Error Code DTS_E_OLEDBERROR. An OLE DB error has occurred. Error code: 0x8004D024.
Error: 0xC00291EC at Execute SQL Task - Max Product ID, Execute SQL Task: Failed to acquire connection "connectionName". Connection may not be configured correctly or you may not have the right permissions on this connection.
The important part of the error being The transaction manager has disabled its support for remote/network transactions. That got me quite a bit farther. I finally realized that I hadn’t configured my local MSDTC! I can’t be certain that this is the minimum configuration to make SSIS transactions work but it worked for me.
During the upgrade to XenApp 7.6 FP3 VDA encountered the following error.
Image may be NSFW. Clik here to view.
Image may be NSFW. Clik here to view.
I was wondered on seeing this popup to restart the server during the upgrade. Well , after further investigation found there is one registry key which was the cause for this issue…
Have navigated to the above mentioned registry path and deleted the contents from the Reg key PendingFileRenameOperations which fixed the issue and completed the upgrade process.
If you have not already heard, SQL Nexus (a next generation SQL Server focused event) will be held on May 2nd – 4th 2016 in Copenhagen, Denmark.
The “idea” for SQL Nexus (w|t) was first conceived in 2012 more as a future pipe dream than anything else and it was something that I had in mind when we delivered the second SQLSaturday Cambridge in 2012 in which we included a dedicated SharePoint track.
At that time, the idea was for a SQL Server centric conference that embraced the whole of the MS Data Platform but SQLSaturday did not feel like the ideal platform for something of the scale required. This vision was discussed with Régis in early 2013 and lay dormant while we were both very busy with alternative commitments. But every great idea needs great people, the right time and the right place and it is through the efforts of Régis Baccaro (b|t) and Kenneth M. Nielsen (b|t) over the last few months that has helped drive this idea forward into reality to what will be a sensational event.
Thanks also must go to the following companies who have been pivotal in making this event possible:
The conference will be held on May 2nd to 4th at Cinemaxx in Copenhagen with one day of pre-conference sessions and 2 full days of breakout sessions. The program for the pre-conference is ready and will feature leading Data Platform professionals including:
If you have not yet submitted a regular session then you have until the 15th February 2016, but why delay? You can submit your sessions through the Call for Speakers page.
If you would just like to attend then visit the website for more information and register!
Top 10 Tips for SQL Server Performance and Resiliency
This article is part 8 in a series on the top 10 most common mistakes that I have seen impacting SQL Server Performance and Resiliency. This post is not all inclusive.
Most common mistake #8: Default TempDB Settings
By default when you install SQL Server the TempDB database is not optimized. For SQL Servers that use the TempDB even moderately, I recommend optimizing it for the best performance. The TempDB is the storage area that SQL Server uses to store data for a short periods of time, information that can be found in the TempDB include temporary tables, and data that is being sorted for query results. The data in the TempDB is so temporary that each time the SQL Server service restarts, the TempDB is recreated.
Due to the specific nature of the data in TempDB and the frequency of use it is important to ensure you have the most optimal configuration.
Optimizing the TempDB is so important that Microsoft is changing how it is installed with SQL Server 2016 to encourage the optimization of Temp DB. How do you optimize TempDB? It’s not difficult at all if you follow these few pointers:
Place your Temp DB on that fastest storage you have. Ultimately this storage should be pounding out a latency less than 5 milliseconds. Does your server have access to SSD storage? If so that is a great place for the TempDB.
There are a great number of studies that have been done to determine the ideal number of files you should split your Temp DB over. With my experience I tend to create one temp DB file for each processor core on the server, however I don’t do this until I find there is some contention in the TempDB.
Grow your TempDB to the size you need it. Your TempDB is going to be recreated each time your service is restarted, so if your default database size is smaller than the normal operational size you are going to have to go through some grow events. Speaking of growth events, it is better to have controlled growth rather than a number of little growth events, so we recommend reviewing the auto growth size.
Top 10 Tips for SQL Server Performance and Resiliency
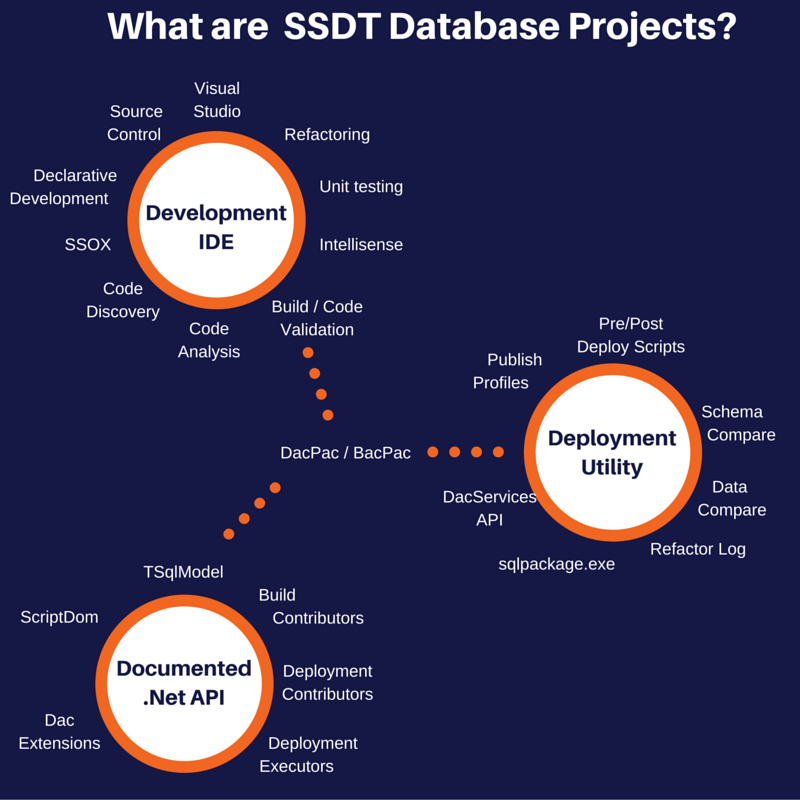
In the final part of this 3 part series on what SSDT actually is I am going to talk about the documented API. What I mean by documented is that Microsoft have published the specification to it so that it is available to use rather than the documentation is particularly good - I warn you it isn't great but there are some places to get some help and I will point them out to you.
There are a number of different API's broadly split into two categories the DacFx and the ScriptDom. The DacFx consists of everything in the diagram around the API's circle except the ScriptDom which is separate.
ScriptDom
For me SSDT really sets SQL Server apart from any other RDBMS and makes development so more professional. The main reason is the declarative approach (I realise this can be replicated to some extent) but also because of the API support - name me one other RDBMS or even NoSql system where you get an API to query and modify the language itself, go on think about it for a minute, still thinking?
The ScriptDom has two ways to use it, the first is to pass it some T-SQL (be it DDL or DML) and it will return a representation of the T-SQL in objects which you can examine and do things to.
The second way it can be used is to take objects and create T-SQL.
I know what you are thinking, why would I bother? It seems pretty pointless to me. Let me assure you that it is not pointless, the first time I used it for an actual issue was where I had a deployment script with about 70 tables in. For various reasons we couldn't guarantee that the tables existed (some tables were moved into another database) the answer would have been to either split the tables into 2 files or manually wrap if exists around each table's deploy script. Neither of these options were particularly appealing at the particular point in the project with the time we had to deliver.
What I ended up doing was using the ScriptDom to parse the file and for each statement, (some were merge statements, some straight inserts, some inserts using outer joins back to the original table and an in-memory table) retrieved the name of the table affected and then generating an if exists and begin / end around the table, I also produced a nice little excel document that showed what tables where there and what method was used to setup the data so we could prioritise splitting the statements up and moving them towards merge statements when we had more time.
Doing this manually would have technically been possible but there are so many things to consider when writing a parser it really is not a very reliable thing to do, just consider these different ways to do the same thing:
I literally got bored thinking of more variations but I am pretty sure I could think of at least 100 ways to get a result set with a single column called a and a single row with a value of 1. If you think that parsing T-SQL is something that is simple then you should give it a go as you will learn a lot (mostly that you should use an API to do it).
One thing that causes some confusion when using the ScriptDom is that to parse any T-SQL unless you just want a stream of tokens you need to use the visitor pattern and implement a class that inherits from TSqlFragmentVisitor - it is really simple to do and you can retrieve all the types of object that you like (CreateProcedure, AlterProcedure etc etc).
So if you have a need to parse T-SQL then use the ScriptDom, it is really simple what is not so simple is the other side of the coin, creating and modifying objects to create T-SQL.
If you need to do this then it is quite hard to work out the exact type of objects you need at the right point, for example if you take this query:
What you end up with is:
SelectStatement that has...
a list of CommonTableExpression that has...
an ExpressionName which is of type Identitfier with a value of "a"
an empty list of Identitiers which are the columns
a QueryExpression that is of type QuerySpecification which has...
a single LiteralInteger as the expression on a SelectScalarExpression as the only element in a list of SelectElement's
the CommonTableExpression has no other specific properties
the SelectStatement also has...
a QueryExpression that is a QuerySpecification which contains....
a list of SelectElement's with one item, a SelectStarExpression
a FromClause that has a list of 1 TableReference's which is a NamedTableReference that is...
a SchemaObjectName that just has an Object name
If you think that it sounds confusing you would be right, but I do have some help for you in the ScriptDomVisualizer - if you give it a SQL statement it will parse it and show a tree of the objects you will get. If you do anything with the ScriptDom then use this as it will help a lot.
The TSql Model is a query-able model of all the objects in an SSDT project, their properties and relationships. That sounds like a mouthful but consider this:
If you just have this script without the model you can use the ScriptDom to find that there is a select statement and a table reference and you could probably also work out that there is a column name but how do you know that there is actually a table called table_name or a column on the table called column_name and also that there isn't already a view or other object called a_room_with_a_view? The TSql Model is how you know!
The TSql Model is actually not that easy to parse (there is help so fear not, I will tell you the hard way to do it then show you the easy way). What you do is to load a model from a dacpac (or you can create a brand new empty one if you like) and then query it for objects of specific types or with a specific name or even just all objects.
So imagine you open a dacpac and want to find the a_room_with_a_view view you could do something like:
If you then wanted to find all the tables that the view referenced then you could examine the properties and relationships to find what you want. It is confusing to get your head around but really useful because if you know what type of object you are interested in then you can tailor your calls to that but if you just what to find all objects that reference a table (i.e. views, other tables via constraints, functions, procedures etc) it means you can really easily do that without having to say "get me all tables that reference this table, get me all functions that reference this table etc etc".
The TSql Model API returns loosely typed objects so everything is a TSqlObject - this is good and bad but I will leave it as an exercise for you to find out why!
DacFx Public Model Tutorial
This is what first allowed me to get into the DacFx, it is the only real documentation I have seen from Microsoft and invaluable to get started
I wrote DacPac Explorer to help teach myself about the DacFx and it turns out it is quite useful and has even been used within Microsoft as a training tool so there you go!
Querying the DacFx API – Getting Column Type Information
If you have tried to do something like get the data type of a column you will appreciate how much work there is to do, well as a special treat there is a github project called Microsoft/DacExtensions and it was written by members of the SSDT team in Microsoft but is open source (I love that!) what it does is take the loosely typed TSqlModel objects and creates strongly typed wrappers so if you want to see what columns are on a table, you query the model for objects of type TSqlTable (or a version specific one if you want) and you get a list of columns as a property rather than having to traverse the relationships etc.
If you do any serious querying of the TSqlModel then look at this as it really will help!
The last three items, the contributors all let you inject your own code into something that SSDT does and change it - this really is huge, normally with tools you get the resulting output and that is it your stuck with it but with SSDT you can completely control certain aspects of how it works.
When you build a project in SSDT a build contributor gets full access to the validated TSqlModel and any properties of the build task so if you wanted to do some validation or change the model when it had been built then you can use this.
Customize Database Build and Deployment by Using Build and Deployment Contributors
When the DacServices have compared your dacpac to a database, deployment plan modifiers are called and can add or remove steps in the plan before the final deployment script is generated. Again this is huge, it is bigger than huger, it is massive. If you want to make sure a table is never dropped or you don't like the sql code that is generated then you can write a utility to change it before it is created - write the utility and use it for every build.
Where deplotment plan modifiers can change the plan and add, edit or remove steps a plan executor gets read only access to the plan and is called when the plan is actually executed. The example on MSDN shows a report of the deployment to give you some idea of what you can do with them.
Walkthrough: Extend Database Project Deployment to Analyze the Deployment Plan
I created a gitter room to answer questions and give advice on writing deployment contributors but I would be more than happy to help answer questions on them or any part of the DacFx so feel free to drop in:
Image may be NSFW. Clik here to view.Ready for a change of pace? Good! Today is a really good time to start looking into one of the more basic concepts related to Extended Event Session management.
Consider the occasional need to change a trace. Maybe you added the wrong event to the trace, or maybe you neglected to include the event in the first place. There is also the possibility that all of the events are correct but the actions or predicates may not be completely ideal for your trace session. What if it is just as simple as a missing target or adding another target to the session? All of these are potential changes to an XEvent session that might be needed.
Today, I will cover how easy it is to modify these sessions without dropping the entire session as many examples on the internet show. Each of the configuration changes just mentioned can be handled through some pretty simple scripts (and yes through the GUI as well).
Altered States
There is no getting around it. To demonstrate how to change event sessions, an event session must first exist. Let’s use the following as the demo session.
CREATE EVENT SESSION [AlteredState] ON SERVER
ADD EVENT sqlserver.auto_stats ( SET collect_database_name = ( 1 )
ACTION ( package0.event_sequence, sqlos.cpu_id, sqlserver.database_id,
sqlserver.database_name )
WHERE ( [database_name] = N'AdventureWorks2014' ) )
ADD TARGET package0.ring_buffer ( SET max_events_limit = ( 666 )
, max_memory = ( 65536 )
, occurrence_number = ( 3 ) )
WITH ( MAX_MEMORY = 4096 KB
, EVENT_RETENTION_MODE = ALLOW_MULTIPLE_EVENT_LOSS
, MAX_DISPATCH_LATENCY = 5 SECONDS
, MAX_EVENT_SIZE = 2048 KB
, MEMORY_PARTITION_MODE = PER_NODE
, TRACK_CAUSALITY = ON
, STARTUP_STATE = ON );
GO
This session starts with a ring_buffer target. There is a single event in the session. This event has a few actions applied to it along with a predicate on the database_name field. I also have several of the settings for this session defined (whether at the custom field level or at the session level).
After deploying this session, I quickly realize that I flubbed it up a bit. I forgot a few things. Since those items are missing, I need to get them added without negatively impacting the already gathered data. Let’s start with the missing target. I don’t know how I missed it, but I completely forgot to add a file target to this session. The file target is a must have, so let’s get it added.
/* target change */
ALTER EVENT SESSION [AlteredState] ON SERVER
ADD TARGET package0.event_file ( SET filename = N'AlteredState'
, max_file_size = ( 50 )
, max_rollover_files = ( 6 ) );
GO
Phew, that problem has been easily rectified. Further review of the session shows the next problem. My manager requires that the dispatch latency be no more than 4 seconds and that the event memory not exceed 4090 kb. My manager is a little intense about some of these settings. To ensure I adhere to his requirements, I need to change my session settings now.
/* set operations change */
ALTER EVENT SESSION [AlteredState] ON SERVER
WITH ( MAX_MEMORY = 4090 KB
, MAX_DISPATCH_LATENCY = 4 SECONDS
);
GO
Good! We are rolling right along here. Fixed a couple of problems real quick with that session and I can continue on with other tasks for the day. Shortly after lunch the manager stops in and asks who changed various database settings. Looking into this session that was just deployed to try and capture some of those events, I get that sinking feeling when I realize that I completely missed that requirement. D’oh! That’s ok for now because I hadn’t turned off the default trace, but I better get the proper event added to the session.
/* add event */
ALTER EVENT SESSION [AlteredState] ON SERVER
ADD EVENT sqlserver.object_altered (
ACTION ( package0.event_sequence, sqlos.cpu_id, sqlserver.database_id,
sqlserver.database_name )
)
;
GO
The next time something changes with the database, it will now be captured. Sadly, too many things are crossing over the desk and I am trying to move too quickly. I forgot to enable the custom field to collect the database name, I better make that adjustment.
/* event custom field change */
ALTER EVENT SESSION [AlteredState] ON SERVER
DROP EVENT sqlserver.object_altered;
ALTER EVENT SESSION [AlteredState] ON SERVER
ADD EVENT sqlserver.object_altered (SET collect_database_name=(1)
ACTION ( package0.event_sequence, sqlos.cpu_id, sqlserver.database_id,
sqlserver.database_name )
)
;
GO
Nice, I have that adjustment made. Unfortunately this is where it does become a bit more complicated. Notice that I had to drop the event from the session first before making that change to the custom field setting for that event? This should be minimal in overall impact since it does not remove the already captured events from the session target. But it is an extra step that must be remembered when making a change that affects an Event within the session.
So far so good. I can capture the events that relate to a database change. I can figure out who made the change and the statement made for the change, right? Nope. I missed that during the setup. I guess I better add that in so I have better information for auditing the changes made to the database. I can start capturing that with the addition of the correct actions.
/* oops wrong actions for the new event */
ALTER EVENT SESSION [AlteredState] ON SERVER
DROP EVENT sqlserver.object_altered;
ALTER EVENT SESSION [AlteredState] ON SERVER
ADD EVENT sqlserver.object_altered (SET collect_database_name=(1)
ACTION ( package0.event_sequence, sqlserver.client_hostname,sqlserver.nt_username,sqlserver.server_principal_name,
sqlserver.database_name, sqlserver.sql_text )
)
;
GO
Everything is now settled in with that session. I go about my merry way for a couple of weeks. Then, one day, I find I need to review the logs to determine who has been changing database settings again. When looking at the log data I discover there are all sorts of object changes being logged to the event session log files. In review of the session definition I figure out the problem. I missed a predicate limiting the captured events to only those that are database type changes. I might as well get that added in.
/* oops, missed that predicate */
ALTER EVENT SESSION [AlteredState] ON SERVER
DROP EVENT sqlserver.object_altered;
ALTER EVENT SESSION [AlteredState] ON SERVER
ADD EVENT sqlserver.object_altered (SET collect_database_name=(1)
ACTION ( package0.event_sequence, sqlos.cpu_id, sqlserver.database_id,
sqlserver.database_name, sqlserver.sql_text )
WHERE ([object_type]='DATABASE')
)
;
GO
This will now change the event session so the object_altered event will only capture “database” type events. These are the types of events that include settings changes at the database level.
Making changes to an event session without needing to drop and recreate the entire session is a pretty powerful tool. If I script that session as it is now configured, I would get the following:
Compare this to the starting session, and it is apparent that all of the changes implemented are now intact.
Altering an Extended Event session is not necessarily a difficult task, but it is a very useful ability. Having this basic skill in your wheelhouse can be very positive and useful for you!
This has been another article in the 60 Days of XE series. If you have missed any of the articles, or just want a refresher, check out the TOC.
In this post, I will try to convince you that using SQL Server Data Tools (SSDT) Database Projects is a really good idea. Recently during a project I've been advocating that it indeed is worth the effort. Since I'm a BI architect, I'm framing this conversation around a data warehouse, but it certainly applies to any type of database.
What is a Database Project in SQL Server Data Tools (SSDT)?
A data warehouse contains numerous database objects such as tables, views, stored procedures, functions, and so forth. We are very accustomed to using SSDT BI projects (formerly BIDS) for SSIS (Integration Services), SSAS (Analysis Services), and SSRS (Reporting Services). However, it's a less common is using SSDT to store the DDL (data definition language) for database objects.
Image may be NSFW. Clik here to view.
Below is an example of how you could structure your database project (am only showing a few tables and views in the screen shots for brevity). You don't have to structure it this way, but in this project it's sorted first by schema, then by object type (table, view, etc), then by object (table name and its DDL, etc).
Image may be NSFW. Clik here to view.
The contents of items in the SSDT DB project are the 'Create Table' statements, 'Create View' statements, 'Create Schema' statements, and so forth. This is based upon “declarative database development” which focuses on the final state desired for an object. For instance, here's the start for a DimDate view:
Image may be NSFW. Clik here to view.
Since the DimDate view resides in the DW schema, the database project would do me the favor of generating an error if the DW schema didn't already exist, like follows:
Image may be NSFW. Clik here to view.
Team Foundation Server does integrate well with database projects (i.e., for storing scripts for database objects such as tables, views, and functions), Integration Services, Analysis Services, and Reporting Services.
There's an online mode as well as offline mode; personally I always use the project-oriented offline mode.
Now that we know about the structure of what's in a project, let's talk next about how we manage changes, such as an alter to add a new column.
Managing Changes To Database Objects
The next big thing to know is that there's a mechanism for managing DDL changes, for instance a new column or a change to a data type. Instead of putting an 'Alter Table' statement into the database project, instead you edit that original 'Create Table' statement which focuses on the final state that includes the new column.
Now let's say you are ready to promote that new column to Dev, QA, or Production. Here's where it gets fun. In the database project you can do a 'Schema Comparison' operation which will compare the DB objects between the project and the database. It will detect the difference and script out the necessary 'Alter Table' script to use in your deployment to Production.
Image may be NSFW. Clik here to view.
The output above tells us there's a data type difference between the project and the database for an address column. This helps us reconcile the differences, then we can generate a script which would have an Alter Table statement for the address column (though in the above case, the address is varchar(150) in the database which probably means the ETL developer widened the column but forgot to circle back to the database project - so there's still a lot of judgment when comparing the project to Dev).
Let's take this one step further. When we're ready to promote to a new environment, we can do a schema comparison between Dev and QA, or QA and Prod, and generate a script that'll contain all of the Creates and Alters that we need to sync up the environments. If you are envisioning how handy this is for deployment purposes, then I've already accomplished my mission. (Keep reading anyway though!)
There's a lot more to know about using schema compare, but let's move next to the benefits of using an SSDT database project.
Benefits of Using a Database Project in SQL Server Data Tools (SSDT)
DB projects serve the following benefits:
Easy availability to DDL for all objects (tables, views, stored procedures, functions, etc) without having to script them out from the server and/or restore a backup. (See additional benefits in the next list if you also integrate with source control, which is highly recommended.)
Functionality to script out schema comparison differences for the purpose of deployment between servers. If you've ever migrated an SSIS package change and then it errored because you forgot to deploy the corresponding table change, then you'll appreciate the schema comparison functionality (if you use it before all deployments that is).
Excellent place for documentation of a database which is easier to see than in extended properties. For example, recently I added a comment at the top of my table DDL that explains why there's not a unique constraint in place for the table.
Provides a location for relevant DML (data manipulation language) statements as well, such as the unknown member rows for a dimension table. Note: DML statements do need to be excluded from the build though because the database project really only understands DDL.
Snapshot of DDL at a point in time. If you'd like, you can generate snapshot of the DDL as of a point in time, such as a major release.
Additional benefits *if* you're using a DB project also in conjunction with source control such as TFS:
Versioning of changes made over time, with the capability to quickly revert to a previous version if an error has occurred or to retrieve a deleted object. Useful comments should be mandatory for all developers who are checking in changes, which provides an excellent history of who, when, and why a change was made. Changes can also be optionally integrated into project management processes (ex: associating a work item from the project plan to the checked-in changeset).
Communicates to team (via check-outs) who is working on what actively which improves team effectiveness and potential impact on related database items.
Tips and Suggestions for Using a SSDT Database Project
Use Inline Syntax. To be really effective for table DDL, I think it really requires working -from- the DB project -to- the database which is a habit change if you're used to working directly in SSMS (Management Studio). To be fair, I still work in SSMS all the time, but I have SSMS and SSDT both open at the same time and I don't let SSDT get stale. The reason I think this is so important is related to inline syntax - if you end up wanting to generate DDL from SSMS in order to "catch up" your database project, it won't always be as clean as you want. Take the following for instance:
Image may be NSFW. Clik here to view.
In the above script I've got some default constraints (which are named because who wants the ugly DB-generated constraint names for our defaults and our foreign keys and such, right?!?). The constraints are all inline -- nice and tidy to read. If you were to script out the table shown above from SSMS, it would generate Alter Table statements for each of the constraints. Except for very small tables, that becomes impossible to validate that the DDL is just how you want it to be. Therefore, I suggest using inline syntax so that your database project SQL statements are all clean and easy to read.
Store Relevant DML in the Project (Build = None). If you have some DML (data manipulation language) statements that are manually maintained and need to get promoted to another environment, that makes them an excellent candidate for being stored in the DB project. Since the database project only understands DDL when it builds the project, the 'Build' property for each DML SQL script will need to be set to None in order to avoid errors. A few examples:
Image may be NSFW. Clik here to view.
Build the Project Frequently. You'll be unpopular with your coworkers if you check something in that doesn't build. So you'll want to develop the habit of doing a build frequently (around once a day if you're actively changing DB objects), and always right after you check anything in. You can find the build options if you right-click the project in Solution Explorer. Sometimes you'll want to choose Rebuild because then it’ll validate every object in the solution whether it changed or not (whereas the Build option only builds objects it detects changed, so although Rebuild takes longer it’s more thorough).
Image may be NSFW. Clik here to view.
One more tip regarding the build - if a schema comparison operation thinks a table exists in the database but not in the project, check the build property. If it's set to None for an actual DDL object, then it will accidentally be ignored in the schema comparison operation. Bottom line: set all DDL objects to build, and any relevant DML to not build.
Do a Schema Comparison Frequently. Regularly running a schema compare is a good habit to be in so that there isn't a big cleanup effort right before it's time to deploy to another environment. Let's say I'm responsible for creating a new dimension. As soon as the SSIS package is done with the DDL for the table and views(s) as appropriate, I'll do a schema compare to make sure I caught everything. If your team is a well-oiled machine, then if you do see something in the schema comparison between the project and the Dev DB, it should be something that you or a coworker is actively working on.
Save the Schema Comparison (SCMP) Settings in Your Project. To make it quick and easy to use (and more likely your whole team will embrace using it), I like to save the schema comparison settings right in the project. You can have various SCMPs saved: Project to Dev DB, Dev DB to QA DB, QA DB to Prod DB, and so forth. It's a big time-saver because you'll want to tell the schema compare to ignore things like users, permissions, and roles because they almost always differ between environments. By saving the SCMP you can avoid the tedious un-checking of those items every single time you generate the comparison.
Image may be NSFW. Clik here to view.
Do a 'Generate Script' for the Schema Comparison; Don't Routinely Use the Update Button. Just to the right of the Update button (which I wish were less prominent) is the Generate Script button. This will create the relevant Create and Alter statements that it detects are necessary based on the differences found. Scripting it out allows you to validate the script before it's executed, and to save the history of exactly what changes are being deployed when (assuming it's being done manually & you're not doing automated continuous deployments to Prod). I also prefer to generate the script over letting SSDT do a straight publish because items that are checked out are still part of a publish and we don't usually want that (though it does depend on how you handle your source control branching).
Image may be NSFW. Clik here to view.
While we're on the subject of the scripts generated by the DB project: a couple of things to know. First, you'll need to run the script in SQLCMD mode (in SSMS, it's found on the Query menu). Second, the scripts are not always perfect. For simple changes, they work really well, but sometimes things get complicated and you need to 'manhandle' them. For instance, there might be data in a table and the script has a check statement in the beginning that prevents any changes and might need to be removed or handled differently.
Separate Installation for SSDT vs SSDT-BI Prior to SQL Server 2016. If you go to create a new project in SSDT and you don't see SQL Server Database Project as an option, that means you don't have the right 'flavor' of SSDT installed yet. Thankfully the tools are being unified in SQL Server 2016, but prior to that you'll need to do a separate installation. The SSDT installation files for Visual Studio 2013 can be found here: https://msdn.microsoft.com/en-us/library/mt204009.aspx.
There's a lot more to know about DB projects in SSDT, but I'll wrap up with this intro. There is a learning curve and some habit changes, but hopefully I've encouraged you to give database projects a try.
Recently, we undertook a project to write a couple of automation tools for the utilities that we use to move data around.
The automation solution involved a couple of SSIS packages that created a few data views, generated some key columns and cross-referenced records with predefined static data to facilitate data comparison. In addition, we also wrote a couple of Coded UI tests which would read configuration parameters from a simple Excel file and run through the utilities so that they can run independently without any need of human interaction.
The issue
Unfortunately, it seems that at least in Visual Studio 2012, one cannot have both – an SSIS project and a Coded UI project. This is because the Coded UI tests fail to build with a “System.ArgumentNullException” error.
Here are the simple steps to reproduce the issue:
Launch VS2012
In an new solution, add a new Integration Services project. Leave defaults and save the solution
In this solution, add a new Coded UI Test project. Leave defaults and save the solution. The solution now has the 2 projects as required
Go to Test -> Windows -> Test Explorer
In the solution explorer, right click on the solution and choose “Build Solution”
Build fails unexpectedly with the following error:
The workaround to build and run the Coded UI tests is to simply unload (removal of the project is not necessary) the SSIS project(s) for the time being. Once the Coded UI tests are done, the SSIS project(s) can be loaded back into the solution before checking it back into source control.
Reader *** H. posted a comment on my last version of this script stating that he got an error when this was run against tables containing sparse columns. Data compression does not support tables with sparse columns, so they should be excluded from this process. I’ve modified this script to correct this. I don’t have any tables with sparse columns in my environment, so thanks to *** for pointing this out!
CREATE PROC [dbo].[up_CompressDatabase]
(
@minCompression FLOAT = .25 /* e.g. .25 for minimum of 25% compression */
,@MaxRunTimeInMinutes INT = 60
,@ExecuteCompressCommand BIT = 0 /* 1 to execute command */
,@DBToScan sysname /* database to compress */
)
AS
SET NOCOUNT ON;
/*
Original script by Paul Nielsen www.SQLServerBible.com March 13, 2008
Modified by Shaun J. Stuart www.shaunjstuart.com February 27, 2013
Sets compression for all objects and indexes in the database needing adjustment
If estimated gain is equal to or greater than min compression parameter
then enables row or page compression, whichever gives greater space savings
If row and page have same gain then, enables row compression
If estimated gain is less than min compression parameter, then compression is set to none
- SJS 2/27/13
- Added @MaxRunTimeInMinutes to limit run length (checked afer each command, so
may run longer) Note: This timer only applies to the actual compression process.
It does not limit the time it takes to perform a scan of all the tables / indexes
and estimate compression savings.
- Sorted compression cursor to compress smallest tables first
- Added flag to execute compression command or not
- Added sort in tempdb option (always)
- Re-wrote slightly to persist initial scan results. Will only re-scan after all tables
have been processed
- SJS 7/17/13
- Modified to only look at data that is not already compressed
- Modified for that any items with null none_size, page_size, or row_size are no longer set as
AlreadyProcessed and now have their sizes calculated (i.e. if process was cancelled before
initial scan was completed)
- Modified so that time limit now applies to compression estimate process as well as actual
compression process
- Only look at partitions that have at least one row
- SJS 8/6/13
- Changed name of dbEstimate table to dbCompressionEstimates for clarity
- Added StatusText column to dbCompressionEstimates and added status messages
- Modified to take database name as input parameter to allow use in utility database
instead of the DB being compressed (Table dbCompressionEstimates, which stores sizes and
compression estimates, is still created in the current database.)
- Note: Compression estimates are only made for the database supplied as an input
parameter. However, that database name is stored in the dbCompressionEstimates table and
will be read from there and used when actually performing the compression. This allows you to
create estimates only for multiple databases (using @ExecuteCompressCommand=0), then perform
the compression across multiple databases later (with @ExecuteCompressCommand=1).
- Removed all references to code that checked already compressed data since this routine now only
looks at uncompressed data.
- SJS 8/21/13
- Put []s around table and index names in compression commands.
- SJS 10/7/13
- Added check to make sure table / index still exists before estimating or performing compression.
- Fixed bug in cursor to determine compression estimates (left out db name in where clause)
- SJS 1/31/14
- Fixed bug where nonclustered indexes were always flagged as no longer present (Thanks to cp
for pointing this out at
http://shaunjstuart.com/archive/2013/10/enabling-data-compression-october-2013-update/comment-page-1/#comment)
- SJS 4/14/14
- Another fix to handle tables with spaces in their names
- SJS 8/12/15
- Put []s around table and schema names in estimate page and row compression commands
- Added edition check
- SJS 10/13/15
- Changed PRINT statements to RAISERROR WITH NOWAITs to output info immediately during execution
- Fixed bug where error was generated when max runtime exceeded
- SJS 1/4/16
- Excluded tables with sparse columns (they do not support compression)
*/
DECLARE @EditionCheck VARCHAR(50);
DECLARE @ProgressMessage VARCHAR(2044);
SELECT @EditionCheck = CAST(SERVERPROPERTY('Edition') AS VARCHAR(50));
IF LEFT(@EditionCheck, 10) <> 'Enterprise'
AND LEFT(@EditionCheck, 9) <> 'Developer'
BEGIN
PRINT 'Database compression is only supported on Enterprise and Developer editions '
+ 'of SQL Server. This server is running '
+ @EditionCheck + '.';
RETURN;
END;
IF ISNULL(@DBToScan, '') NOT IN (SELECT
[name]
FROM sys.databases)
BEGIN
SELECT 'Database ' + ISNULL(@DBToScan,
'NULL')
+ ' not found on server.';
RETURN;
END;
DECLARE @CompressedCount INT;
SET @CompressedCount = 0;
DECLARE @SQL NVARCHAR(MAX);
DECLARE @ParmDefinition NVARCHAR(100);
DECLARE @TestResult NVARCHAR(20);
DECLARE @CheckString NVARCHAR(1000);
DECLARE @StartTime DATETIME2;
SET @StartTime = CURRENT_TIMESTAMP;
DECLARE @CurrentDatabase sysname;
SET @CurrentDatabase = DB_NAME();
IF OBJECT_ID('tempdb..##ObjEst', 'U') IS NOT NULL
DROP TABLE ##ObjEst;
CREATE TABLE ##ObjEst
(
PK INT IDENTITY
NOT NULL
PRIMARY KEY
,object_name VARCHAR(250)
,schema_name VARCHAR(250)
,index_id INT
,partition_number INT
,size_with_current_compression_setting BIGINT
,size_with_requested_compression_setting BIGINT
,sample_size_with_current_compression_setting
BIGINT
,sample_size_with_requested_compresison_setting
BIGINT
);
IF NOT EXISTS ( SELECT 1
FROM sys.objects
WHERE object_id = OBJECT_ID(N'[dbo].[dbCompressionEstimates]')
AND type IN (N'U') )
BEGIN
CREATE TABLE dbo.dbCompressionEstimates
(
PK INT IDENTITY
NOT NULL
PRIMARY KEY
,DatabaseName sysname
,schema_name VARCHAR(250)
,object_name VARCHAR(250)
,index_id INT
,ixName VARCHAR(255)
,ixType VARCHAR(50)
,partition_number INT
,data_compression_desc VARCHAR(50)
,None_Size INT
,Row_Size INT
,Page_Size INT
,AlreadyProcessed BIT
,StatusText VARCHAR(75)
);
END;
/*
If all objects have been processed, rescan and start fresh. Useful for catching
added objects since last scan. But beware - this is I/O intensive and can take a while.
*/
IF NOT EXISTS ( SELECT 1
FROM dbo.dbCompressionEstimates
WHERE AlreadyProcessed = 0
AND DatabaseName = @DBToScan )
BEGIN
SET @ProgressMessage = 'No unprocessed items found. Starting new scan.';
RAISERROR(@ProgressMessage,0,1) WITH NOWAIT;
DELETE FROM dbo.dbCompressionEstimates
WHERE DatabaseName = @DBToScan;
SET @SQL = 'USE [' + @DBToScan + '];
INSERT INTO [' + @CurrentDatabase
+ '].dbo.dbCompressionEstimates
(DatabaseName
,schema_name
,object_name
,index_id
,ixName
,ixType
,partition_number
,data_compression_desc
,AlreadyProcessed
,StatusText)
SELECT ''' + @DBToScan
+ '''
,S.name
,O.name
,I.index_id
,I.name
,I.type_desc
,P.partition_number
,P.data_compression_desc
,0 AS AlreadyProcessed
,''Initial load'' AS StatusText
FROM [' + @DBToScan
+ '].sys.schemas AS S
JOIN [' + @DBToScan
+ '].sys.objects AS O ON S.schema_id = O.schema_id
JOIN [' + @DBToScan
+ '].sys.indexes AS I ON O.object_id = I.object_id
JOIN [' + @DBToScan
+ '].sys.partitions AS P ON I.object_id = P.object_id
AND I.index_id = P.index_id
WHERE O.TYPE = ''U''
AND P.data_compression_desc = ''NONE''
AND O.object_id NOT IN (SELECT object_id
FROM [' + @DBToScan + '].sys.columns WHERE is_sparse = 1)
AND P.rows > 0;'; -- only look at objects with data
EXEC (@SQL);
END;
-- Determine Compression Estimates
SET @ProgressMessage = 'Beginning compression estimate phase.';
RAISERROR(@ProgressMessage,0,1) WITH NOWAIT;
DECLARE @PK INT
,@DatabaseName sysname
,@Schema VARCHAR(150)
,@object VARCHAR(150)
,@DAD VARCHAR(25)
,@partNO VARCHAR(3)
,@indexID VARCHAR(3)
,@ixName VARCHAR(250)
,@ixType VARCHAR(50)
,@Recommended_Compression VARCHAR(10);
DECLARE cCompress CURSOR FAST_FORWARD
FOR
SELECT schema_name
,object_name
,index_id
,partition_number
,data_compression_desc
,ixName
FROM dbo.dbCompressionEstimates
WHERE (None_Size IS NULL
OR Row_Size IS NULL
OR Page_Size IS NULL)
AND DatabaseName = @DBToScan;
OPEN cCompress;
FETCH cCompress INTO @Schema, @object, @indexID,
@partNO, @DAD, @ixName;
WHILE @@Fetch_Status = 0
BEGIN
/* evaluate objects with no compression */
IF DATEDIFF(mi, @StartTime,
CURRENT_TIMESTAMP) < @MaxRunTimeInMinutes
BEGIN
/* First, make sure the table / index still exists (in case this
process is run over multiple days */
IF @indexID = 0
BEGIN /* heaps */
SET @CheckString = 'IF object_ID('''
+ @DBToScan + '.'
+ @Schema + '.'
+ @object
+ ''') IS NULL
BEGIN
SELECT @TestResultOUT = ''Does Not Exist''
END
ELSE
BEGIN
SELECT @TestResultOUT = ''Exists''
END';
END;
ELSE
BEGIN /* indexes */
SET @CheckString = 'IF NOT EXISTS (SELECT 1 FROM ['
+ @DBToScan
+ '].[sys].[indexes] WHERE [name] ='''
+ @ixName
+ ''' AND OBJECT_ID('''
+ '[' + @DBToScan
+ ']' + '.['
+ @Schema + '].['
+ @object + ']'''
+ ') = [object_id])
BEGIN
SELECT @TestResultOUT = ''Does Not Exist''
END
ELSE
BEGIN
SELECT @TestResultOUT = ''Exists''
END';
END;
SET @ParmDefinition = '@TestResultOUT varchar(20) OUTPUT';
EXECUTE sp_executesql
@CheckString
,@ParmDefinition
,@TestResultOUT = @TestResult OUTPUT;
IF @TestResult = 'Exists'
BEGIN
IF @DAD = 'none'
BEGIN
/* estimate Page compression */
SET @SQL = 'USE ['
+ @DBToScan
+ '];
INSERT ##ObjEst
(object_name
,schema_name
,index_id
,partition_number
,size_with_current_compression_setting
,size_with_requested_compression_setting
,sample_size_with_current_compression_setting
,sample_size_with_requested_compresison_setting)
EXEC sp_estimate_data_compression_savings
@Schema_name = ['
+ @Schema
+ ']
,@object_name = ['
+ @object
+ ']
,@index_id = '
+ @indexID
+ '
,@partition_number = '
+ @partNO
+ '
,@data_compression = ''PAGE'';';
SET @ProgressMessage = 'Estimating PAGE compression for '
+ '['
+ @DBToScan
+ '].['
+ @Schema
+ '].['
+ @object
+ '], '
+ 'index id '
+ CAST(@indexID AS VARCHAR(3))
+ ', '
+ 'partition number '
+ CAST(@partNO AS VARCHAR(3));
RAISERROR(@ProgressMessage,0,1) WITH NOWAIT;
EXEC (@SQL);
UPDATE
dbo.dbCompressionEstimates
SET
None_Size = O.size_with_current_compression_setting
,Page_Size = O.size_with_requested_compression_setting
,StatusText = 'Compression estimate 50% complete'
FROM
dbo.dbCompressionEstimates D
JOIN ##ObjEst O
ON D.schema_name = O.schema_name
AND D.object_name = O.object_name
AND D.index_id = O.index_id
AND D.partition_number = O.partition_number;
DELETE
##ObjEst;
-- estimate Row compression
SET @SQL = 'USE ['
+ @DBToScan
+ '];
INSERT ##ObjEst
(object_name
,schema_name
,index_id
,partition_number
,size_with_current_compression_setting
,size_with_requested_compression_setting
,sample_size_with_current_compression_setting
,sample_size_with_requested_compresison_setting)
EXEC sp_estimate_data_compression_savings
@Schema_name = ['
+ @Schema
+ ']
,@object_name = ['
+ @object
+ ']
,@index_id = '
+ @indexID
+ '
,@partition_number = '
+ @partNO
+ '
,@data_compression = ''ROW'';';
SET @ProgressMessage = 'Estimating ROW compression for '
+ '['
+ @DBToScan
+ '].['
+ @Schema
+ '].['
+ @object
+ '], '
+ 'index id '
+ CAST(@indexID AS VARCHAR(3))
+ ', '
+ 'partition number '
+ CAST(@partNO AS VARCHAR(3));
RAISERROR(@ProgressMessage,0,1) WITH NOWAIT;
EXEC (@SQL);
UPDATE
dbo.dbCompressionEstimates
SET
Row_Size = O.size_with_requested_compression_setting
,StatusText = 'Compression estimate 100% complete'
FROM
dbo.dbCompressionEstimates D
JOIN ##ObjEst O
ON D.schema_name = O.schema_name
AND D.object_name = O.object_name
AND D.index_id = O.index_id
AND D.partition_number = O.partition_number;
DELETE
##ObjEst;
END; /* end evaluating objects with no compression */
END;
ELSE /* table or index no longer exists */
BEGIN
SET @ProgressMessage = 'Encountered table or index that no longer exists at compression estimate stage. Skipping.';
RAISERROR(@ProgressMessage,0,1) WITH NOWAIT;
UPDATE dbo.dbCompressionEstimates
SET AlreadyProcessed = 1
,StatusText = 'Object no longer exists at compression estimate stage'
WHERE schema_name = @Schema
AND object_name = @object
AND index_id = @indexID
AND partition_number = @partNO
AND data_compression_desc = @DAD
AND DatabaseName = @DBToScan;
END;
FETCH NEXT FROM cCompress INTO @Schema,
@object, @indexID, @partNO,
@DAD, @ixName;
END; -- end time check block
ELSE
BEGIN
SET @ProgressMessage = 'Max runtime reached. No compression performed. Compression estimate still processing. Exiting...';
RAISERROR(@ProgressMessage,0,1) WITH NOWAIT;
CLOSE cCompress;
DEALLOCATE cCompress;
DROP TABLE ##ObjEst;
RETURN;
END;
END; -- end while loop
CLOSE cCompress;
DEALLOCATE cCompress;
SET @ProgressMessage = 'Compression estimate scan complete.';
RAISERROR(@ProgressMessage,0,1) WITH NOWAIT;
--END
/* End evaluating compression savings. Now do the actual compressing. */
SET @ProgressMessage = 'Beginning compression.';
RAISERROR(@ProgressMessage,0,1) WITH NOWAIT;
/* Do not process objects that do not meet our compression criteria */
SET @ProgressMessage = 'Skipping empty objects and objects that do not meet '
+ 'the minimum compression threshold.';
RAISERROR(@ProgressMessage,0,1) WITH NOWAIT;
UPDATE dbo.dbCompressionEstimates
SET AlreadyProcessed = 1
,StatusText = 'Best compression method less than minCompression threshold'
WHERE (1 - (CAST(Row_Size AS FLOAT) / None_Size)) < @minCompression
AND (Row_Size <= Page_Size)
AND None_Size > 0
AND AlreadyProcessed = 0;
UPDATE dbo.dbCompressionEstimates
SET AlreadyProcessed = 1
,StatusText = 'Best compression method less than minCompression threshold'
WHERE (1 - (CAST(Page_Size AS FLOAT) / None_Size)) < @minCompression
AND (Page_Size <= Row_Size)
AND None_Size > 0
AND AlreadyProcessed = 0;
/* Do not set compression on empty objects */
UPDATE dbo.dbCompressionEstimates
SET AlreadyProcessed = 1
,StatusText = 'No data in table to compress'
WHERE None_Size = 0
AND AlreadyProcessed = 0;
-- set the compression
DECLARE cCompress CURSOR FAST_FORWARD
FOR
SELECT DatabaseName
,schema_name
,object_name
,partition_number
,ixName
,ixType
,CASE WHEN (1
- (CAST(Row_Size AS FLOAT)
/ None_Size)) >= @minCompression
AND (Row_Size <= Page_Size)
THEN 'Row'
WHEN (1
- (CAST(Page_Size AS FLOAT)
/ None_Size)) >= @minCompression
AND (Page_Size <= Row_Size)
THEN 'Page'
ELSE 'None'
END AS Recommended_Compression
,PK
FROM dbo.dbCompressionEstimates
WHERE None_Size <> 0
AND (CASE WHEN (1
- (CAST(Row_Size AS FLOAT)
/ None_Size)) >= @minCompression
AND (Row_Size <= Page_Size)
THEN 'Row'
WHEN (1
- (CAST(Page_Size AS FLOAT)
/ None_Size)) >= @minCompression
AND (Page_Size <= Row_Size)
THEN 'Page'
ELSE 'None'
END <> data_compression_desc)
AND AlreadyProcessed = 0
ORDER BY None_Size ASC; /* start with smallest tables first */
OPEN cCompress;
FETCH cCompress INTO @DatabaseName, @Schema, @object,
@partNO, @ixName, @ixType,
@Recommended_Compression, @PK; -- prime the cursor;
WHILE @@Fetch_Status = 0
BEGIN
IF @ixType = 'Clustered'
OR @ixType = 'heap'
BEGIN
SET @SQL = 'USE ['
+ @DatabaseName + '];
ALTER TABLE [' + @Schema
+ '].[' + @object
+ '] Rebuild with (data_compression = '
+ @Recommended_Compression
+ ', SORT_IN_TEMPDB=ON)';
SET @CheckString = 'IF object_ID('''
+ @DatabaseName + '.'
+ @Schema + '.' + @object
+ ''') IS NULL
BEGIN
SELECT @TestResultOUT = ''Does Not Exist''
END
ELSE
BEGIN
SELECT @TestResultOUT = ''Exists''
END';
END;
ELSE /* non-clustered index */
BEGIN
SET @SQL = 'USE ['
+ @DatabaseName + '];
ALTER INDEX [' + @ixName
+ '] on [' + @Schema + '].['
+ @object
+ '] Rebuild with (data_compression = '
+ @Recommended_Compression
+ ',SORT_IN_TEMPDB=ON)';
SET @CheckString = 'IF NOT EXISTS (SELECT 1 FROM ['
+ @DBToScan
+ '].[sys].[indexes] WHERE [name] ='''
+ @ixName
+ ''' AND OBJECT_ID(''' + '['
+ @DBToScan + ']' + '.['
+ @Schema + '].[' + @object
+ ']'''
+ ') = [object_id])
BEGIN
SELECT @TestResultOUT = ''Does Not Exist''
END
ELSE
BEGIN
SELECT @TestResultOUT = ''Exists''
END';
END;
IF DATEDIFF(mi, @StartTime,
CURRENT_TIMESTAMP) < @MaxRunTimeInMinutes
BEGIN
IF @ExecuteCompressCommand = 1
BEGIN
/* verify that table / index still exists before doing anything */
SET @ParmDefinition = '@TestResultOUT varchar(20) OUTPUT';
EXECUTE sp_executesql
@CheckString
,@ParmDefinition
,@TestResultOUT = @TestResult OUTPUT;
IF @TestResult = 'Exists'
BEGIN
UPDATE
dbo.dbCompressionEstimates
SET
StatusText = 'Compressing data...'
WHERE
PK = @PK;
SET @ProgressMessage = 'Compressing table/index: '
+ '[' + @ixName
+ '] on ['
+ @Schema
+ '].['
+ @object
+ '] in database '
+ @DatabaseName;
RAISERROR(@ProgressMessage,0,1) WITH NOWAIT;
EXEC sp_executesql
@SQL;
UPDATE
dbo.dbCompressionEstimates
SET
AlreadyProcessed = 1
,StatusText = 'Compression complete'
WHERE
PK = @PK;
SET @CompressedCount = @CompressedCount
+ 1;
END;
ELSE
BEGIN
SET @ProgressMessage = 'Encountered table or index that no longer exists at compression stage. Skipping.';
RAISERROR(@ProgressMessage,0,1) WITH NOWAIT;
UPDATE
dbo.dbCompressionEstimates
SET
AlreadyProcessed = 1
,StatusText = 'Object no longer exists at compression stage'
WHERE
PK = @PK;
END;
END;
ELSE
BEGIN
SET @ProgressMessage = 'Command execution not enabled. Command is:'
+ @SQL;
RAISERROR(@ProgressMessage,0,1) WITH NOWAIT;
END;
END;
ELSE
BEGIN
SET @ProgressMessage = 'Max runtime reached. Some compression performed. Exiting...';
RAISERROR(@ProgressMessage,0,1) WITH NOWAIT;
CLOSE cCompress;
DEALLOCATE cCompress;
DROP TABLE ##ObjEst;
RETURN;
END;
FETCH cCompress INTO @DatabaseName,
@Schema, @object, @partNO, @ixName,
@ixType, @Recommended_Compression,
@PK;
END;
CLOSE cCompress;
DEALLOCATE cCompress;
SET @ProgressMessage = 'Objects compressed: '
+ CONVERT(VARCHAR(10), @CompressedCount);
RAISERROR(@ProgressMessage,0,1) WITH NOWAIT;
DROP TABLE ##ObjEst;
RETURN;
On February 6, 2016, Cleveland is hosting a free training event for SQL Server. This has a lot of the great stuff from the big, paid events, and skips some of the negatives.
There’s a great team from the North Ohio SQL Server Users Group that took on a very difficult task to put all of this together. They hand selected every presentation, being forced to turn away over half of the abstracts and many speakers. What they came up with was a variety of topics that span the breadth of SQL Server and the experience levels of the professionals working with databases.
What is this SQL Saturday?
For those of you who have never been to a SQL Saturday, here’s how this one works. Other SQL Saturdays will vary from this slightly, but not too much.
There are 6 training rooms with hour-long presentations running simultaneously in each. You move from room to room between each session choosing the ones that apply to you the most. The schedule for the sessions is posted in advance, and it’s impressive.
An optional $10 lunch, which is typically very obvious that no one is making a profit off of, is the closest thing the event has to an entrance fee. The stuff you’d expect to cost you is provided by volunteers and sponsors who pull together the venue, presenters, and community for you.
There’s time to network with vendors, attendees, and speakers before the event, during breaks and lunch, and often end up in conversations that last throughout the next session. This differs from the big events in that it’s much smaller and personable with most attendees being relatively local. The people you meet at a regional event like this are going to be more relevant to your life because they’re part of your local community.
The event at Hyland Software concludes with prizes ranging from $100 gift cards to new laptops being handed out to random attendees. Yes, you can basically get paid to go to free training, which I still don’t quite understand.
Then there’s the after-party, also provided by the SQL Saturday volunteers and sponsors. There’s food, fun, and more time to get to know some great people.
The venue can’t hold everyone who should come, and often can’t hold everyone who wants to come. Register now to make sure there’s room for you, and make sure to cancel if your plans fall through.
What is SQL Saturday?
Not just this event, what is SQL Saturday as a whole? It’s a program specifically set up to help everyone in the community to develop.
The obvious people benefiting are the attendees who get a chance to see all the sessions and meet the vendors. You can see how they would benefit from here, but not quite how much until you’re at the event.
The less obvious are the speakers, some speaking publically for the first time. As one of the speakers, I can personally say that I’ve grown more as a person and as a professional than I thought possible. It’s a step I highly recommend, and one I’m very grateful to have with SQL Saturday.
The even less obvious are the vendors. They’re speaking to the public, not just their established customers, getting candid feedback on what works, what doesn’t work, and how they can make their offerings better. Even if they don’t make a single sale from attending the event, they can always come out ahead.
These event are around the world with one or more occurring almost every weekend of the year as an annual event in most major cities. See SQL Saturday’s website for a full list of what’s coming up. If your city isn’t coming up soon, look in past events because most cities hold it about the same time every year.
Who’s speaking?
Where do I start? Well, by listing EVERYONE on the current schedule, along with the blogs and twitter handles I’m aware of.
Note that the schedule may change some before the event, but it never changes too much.
What do we ask of you?
Show up.
Despite the amazing list of speakers, we’re all volunteers. That means we do it because we want to do it, and truly enjoy it. If you want to help us enjoy it even more, be involved. Talk to us and the other attendees, ask questions, and give feedback.
If you want to absolutely blow us away, get in touch afterwards and let us know the difference it made for you. Yes, we want this, it will absolutely make our day! Let the organizers know what you think of the event. Tell the presenters how you were able to use their advice at work, and even ask questions down the road. I used to think this was imposing, but now I realize this is the one of the most awesome compliments you can get.