Previously I covered what a data lake is (including the Azure Data Lake and enhancements), and now I wanted to touch on the main reason why you might want to incorporate a data lake into your overall data warehouse solution.
To refresh, a data lake is a landing zone, usually in Hadoop, for disparate sources of data in their native format. Data is not structured or governed on its way into the data lake. This eliminates the upfront costs of data ingestion, especially transformation. Once data is in the lake, the data is available to everyone. You don’t need a priority understanding of how data is related when it is ingested, rather, it relies on the end-user to define those relationships as they consume it. Data governorship happens on the way out instead of on the way in. This makes a data lake very efficient in processing huge volumes of data. Another benefit is the data lake allows for data exploration and discovery, to find out if data is useful or to create a one-time report.
The disadvantages of a data lake are that it is usually not useful for analytical processing. If you need to return queries very fast, as in a few seconds or less, the data lake won’t give you that performance. Also the data is usually not clean, and it’s not easy to join the data. And finally, it can be difficult for less technical people to explore and ask questions of the data (i.e. having to write a Spark job in Java). This is where federated query technologies like PolyBase help by allowing end users to use regular SQL to access data in the data lake as well as combine that data with data in an RDBMS. What many people don’t realize is data governance needs to be applied to a data lake, just like it needs to be applied to a data warehouse, if people will try to report from it (as opposed to passing the raw data in the data lake to a RDBMS where it will be cleaned and accessible to end users). This means you should have multiple stages of data in the data lake, such as: raw, cleaned, mastered, test, production ready. Don’t make the data lake become a collection of silos (a data swamp).
A data warehouse, which is a central repository of integrated data from one or more disparate sources, has many benefits. However, it takes a lot of time and money to get the data ready to be analyzed, performing the tasks to acquire the data, prep it, govern it, and finding keys to join the data. Often integration is done without a clear visibility into the value that is going to be extracted from it. Just because you can join and relate the data, if you have not figured out the value, the risk is that if turns out not to be valuable you have wasted a lot of time. Also, if relationships change between new data sources it becomes a challenge. The big benefit of a data warehouse is speed of queries. If you create a dashboard where a user can slice and dice the data, you want to be hitting a data warehouse. You get the speed because a data warehouse can be in a RDBMS as well as a star schema format which will give you optimal performance, much more than you would get from querying a data lake.
So using both a data lake and a data warehouse is the ideal solution. The best way to see this in action is an architecture diagram that lists the many possible technologies and tools that you can use:
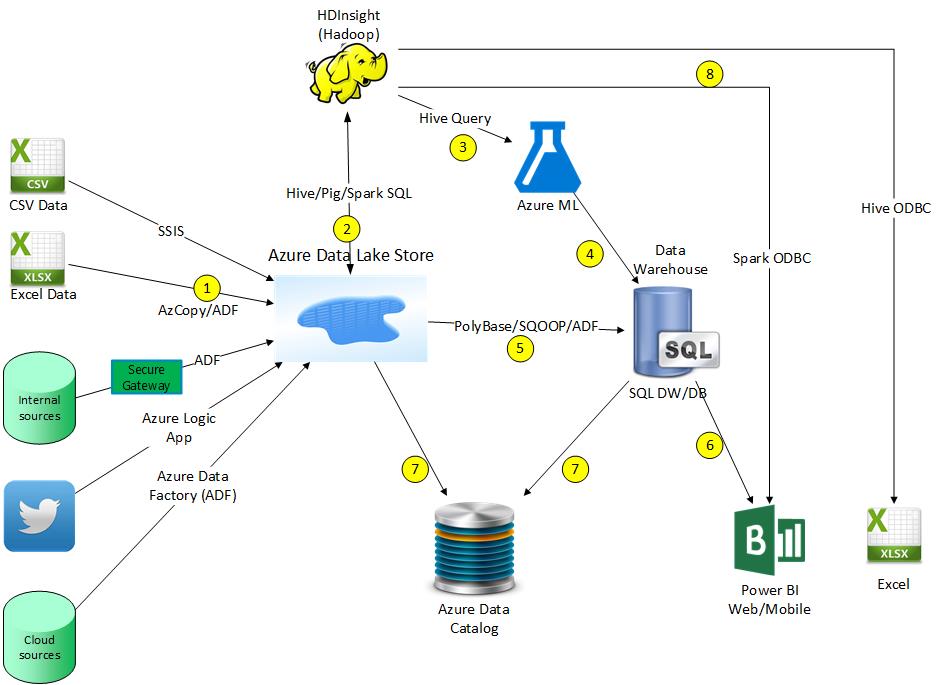
The details on the numbered steps in the above diagram (which is cloud solution, but it can access on-prem sources):
1) Copy source data into the Azure Data Lake Store (twitter data example)
2) Massage/filter the data using Hadoop (or skip using Hadoop and use stored procedures in SQL DW/DB to massage data after step #5)
3) Pass data into Azure ML to build models using Hive query (or pass in directly from Azure Data Lake Store)
4) Azure ML feeds prediction results into the data warehouse
5) Non-relational data in Azure Data Lake Store copied to data warehouse in relational format (optionally use PolyBase with external tables to avoid copying data)
6) Power BI pulls data from data warehouse to build dashboards and reports
7) Azure Data Lake captures metadata from Azure Data Lake Store and SQL DW/DB
8) Power BI and Excel can pull data from the Azure Data Lake Store via HDInsight
The beauty in the above diagram is you are separating out storage (Azure Data Lake Store) from compute (HDInsight), so you can shut down your HDInsight cluster to save costs without affecting the data. So you can fire up a HDInsight cluster, scale it up, and do processing, and then shut it down when not in use or scale it down.
There are so many possible technologies and tools that can be used. You can even have the data from a data lake feed a NoSQL database, a SSAS cube, a data mart, or go right into Power BI Desktop. There is not a cookie-cutter solution – it depends on such things as the type of data, the size, the skill set, the required speed, the allowed company software, the company risk or comfort level (bleeding edge, leading edge), etc. For example, even though the data lake is a staging area of the data warehouse, operational reports that run at night can be generated from the data lake.
If you already have a data warehouse solution, incorporating a data lake does not mean all existing sources should land in the data lake. Rather, it can be used for new sources and down the road you can migrate some of the older sources. For now those existing sources can bypass the data lake and go right into the data warehouse.
Another big use for a data lake is for offloading data (i.e. historical data) from other systems, such as your data warehouse or operational systems.
The goal of this post is to educate you on all the tools so you choose the best one. The bottom line is a data lake should be a key component to your modern data architecture.
Data Lakes – Five Tips to Navigating the Dangerous Waters